Simple Scrapy Using Python
Helpful to new-hand in web scraping.

近日某深夜,一位在远方实习的舍友来请求我的帮助…他需要从一个网站上搜集近两年总共5万多条的基金季报数据(该数据属于公开数据),并把数据写入 Excel 文件保存。这是一个非常非常简单、基础的爬虫项目,很适合入门。
什么是 Python 爬虫:
简单地说,爬虫就是用程序代替人工来访问大量结构相似的网页,解析这些网页的内容,提取出自己想要的数据,最后并把收集到的数据储存到本地,用于进一步的研究分析。以上这些工作全部由编写好的 Python 程序自动化地完成。
爬虫可以节省大量人力时间,完成人力所不能及的大规模网络数据采集任务。比如:
- 访问一个信息公示网页内的几百页、上万个链接,从每个子链接点进去的表格中提取信息,形成一张汇总表格。
- 下载关于某个主题的几百万张图片到本地的一个指定文件夹内。
- 搜索、下载满足某个条件的一系列视频到本地。
- 收集相同商品在不同市场上的价格,并实时更新。
BTW, 舍友先拿着网站去问了淘宝代写爬虫的店家,这么简单的一个爬虫,店家居然要价 200…我
也有点心动实在有点看不过去,钱有这么好赚吗…
爬虫需谨慎,本文的代码和数据都仅用于编程技术学习,请勿用于其他任何用途,否则造成的后果与本文作者无关。
前提条件
在真正编写一个爬虫之前,我们需要 Python 环境。这里强烈推荐直接安装 Anaconda (Python 3+),它集成了 Python 环境、用于数据科学的 Python 库和一系列非常实用的工具。
安装 Anaconda
从 Anaconda 下载页面安装 Anaconda。安装时有一步会询问是否将 python 加入环境变量(PATH),在那里请勾选“是”,继续安装。
安装完成后,命令行输入 python 并回车,会出现类似下面的提示,说明环境搭建成功。
Python 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)] ::
Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
如果此处报错,说明没有把
python添加到系统环境变量里,查找 “Anaconda 添加环境变量” 的相关教程即可,这里不再赘述。
你还需要一个可以解析网络请求的浏览器(比如谷歌浏览器)
爬虫的本质是替你上网冲浪模仿浏览器的行为访问网站,区别在于,得到服务器响应之后,爬虫和人工访问用的浏览器做的事不一样:
- 人工访问网站时,浏览器做的事:浏览器会向网站的服务器发送请求,得到服务器返回的文件,然后在浏览器中解析这些文件,形成内容、版式,最后构成一个网页展示给我们看。
- 程序访问网站时,程序所做的事:程序模仿浏览器,向网站的服务器发送和浏览器一模一样的请求,得到一模一样的返回文件,然后在程序中直接解析这些文件,直接提取我们想要的内容、数据,把它们储存到本地。
显然,在一开始,我们的爬虫并不是一个成熟的爬虫,它需要我们代码的指引。为此,我们首先要知道浏览器请求这个网站时是怎么做的,才能让 Python 爬虫模仿它。
在谷歌浏览器中,点击右键-检查(或者按 F12)进入浏览器控制台,在控制台中选择 Network 签页,按红点旁边的禁止图案清空已有记录,再访问我们要爬的网页,就可以读取到浏览器的发送的请求,以及服务器返回的具体文件了。其他浏览器有类似功能即可。
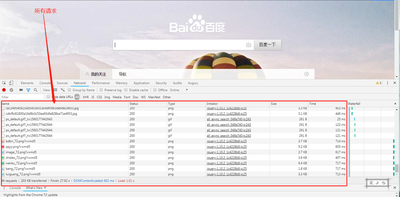
分析网站:我们要爬什么?
先分析网站很重要,可以帮我们发现最合适、高效的方法。
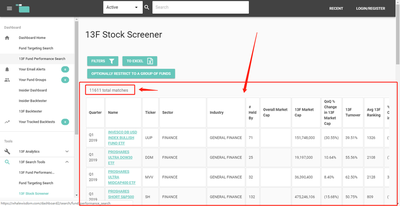
从这里打开我们要爬取的网站,我们可以看到,页面的表格就是我们想要获取的基金季报数据,默认只显示 2019 年第一季度的数据。我们通过筛选按钮,筛选出从 2018 年第一季度至 2019 年第一季度的所有基金季报数据(共 58169 条)。
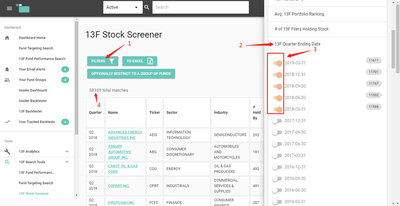
现在,网站页面显示,我们要爬取的表格有 2300 多页,每一页有 20 多行。
要想把这些数据全部收集到 Excel 表格中,用人工显然是不可能的……爬虫的优势这时就体现出来啦!
通过浏览器捕获请求
在设计任何爬虫时,我们首先都想尝试知道浏览器如何请求到新数据的,如果知道这一点,爬虫只需要构造一模一样的请求,就可以拿到数据,这是最令人开心的简单的爬虫情形。
如何捕获到这个关键的请求呢?一个简单的方法:现代的网站开发中,为了提高用户体验,在需要更新某些内容时,网页往往只会更新 需要更新的那部分 ,其他部分不会更新。因此,我们让这个网站面临一个只需要更新数据的情形 —— 翻页。
在谷歌浏览器中,点击右键-检查(或者按 F12)进入浏览器控制台,在控制台中选择 Network 签页,按红点旁边的禁止图案清空已有记录,然后翻页。我们十分欣慰地发现,在翻页的过程中,浏览器只向服务器发送了唯一一条请求,因此我们基本可以确定,新一页的数据就在这条新请求的返回结果中。
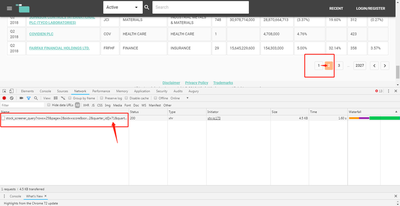
点击该请求,
- Headers 签页描述了浏览器向哪个地址请求数据、传递的参数是什么,以及服务器如何响应该请求。
- Preview 签页展示了服务器返回的内容
我们选择 Preview 页签,看到的是一个结构化的数据,展开其中 rows 字段,可以看到里面就是我们在这一页想要的数据。
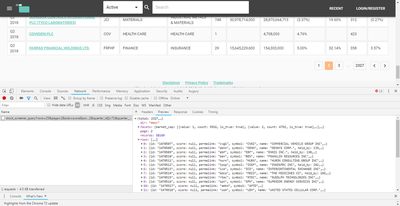
找到关键请求之后,我们选择 Headers 页签,找到请求的 URL 和请求的方式(GET)。
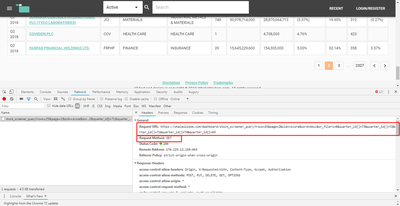
在 Headers 页签的最下方找到请求的参数。这个参数是被传递给服务器,服务器可以根据参数返回正确的数据。对照参数和当前网页的内容,可以看出:
rows是每一页的行数page是当前页码(连续翻页观察请求的网址,也可以看出)sord是排序顺序(升序/降序)sidx是排序依据的字段名quarter_id[]则是之前选择的各个时间范围。
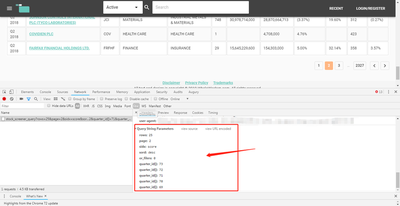
服务器根据这些参数查询数据,然后把数据返回给浏览器(这里被我们捕获),浏览器把数据填充进网页中,更新新一页的表格,完成翻页。整个请求的逻辑十分清晰~~,爬虫写起来也就十分容易~~。
编写爬虫
新建文件 web_scrapy.py,用编辑器打开。
没有安装编辑器的话,强烈推荐安装 VS Code,一个免费、开源又功能强大的编辑器,你不会后悔的。
首先引入我们需要用到的三个库,
# web_scrapy.py
import time # 时间库,这里用于限制爬取的速度,否则程序的请求过快,可能影响到对方服务器的正常运行
import requests # 访问互联网的库,这里用于模拟浏览器发送请求,并接受返回数据
import pandas as pd # 数据处理库,这里用于将数据写入 Excel
设定爬虫的配置,后面会引用到这些变量。配置写在最前面,方便整个爬虫的维护。
speed_rate = 2 # 爬虫速度。这里把速度限制在人工访问的水平(每 2 秒请求一次),尽量避免影响服务器的正常运行
row_per_page = 100 # 每页请求 100 行,经过尝试,这是一次请求能得到的最大行数,默认是每页 25 行,我们这样设置能极大提升爬虫效率,也使爬取速度能被限制成更慢的速度,避免影响对方服务器的正常运行
尝试请求第一个页面,
# web_scrapy.py
res = requests.get('https://whalewisdom.com/dashboard/stock_screener_query?rows=%s&page=1&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69' % (row_per_page))
records = res.json()
requests.get()函数里传入的是请求的目标 URL,我们从刚才捕获的请求中得到了单个页面的 URL,该函数使用 GET 方式向指定的 URL 发送网络请求- URL 中,参数
page=1,我们请求的是第一页的数据 - URL 中,参数
rows=%s,使用了格式化字符串,将百分号后面的row_per_page变量输出到%s位置,从而配置了每页请求的行数。若看不懂该行语法,请复习 Python 格式化字符串。 requests.get()返回的结果是一个 Response 对象,调用它的json()方法,我们得到 json 格式的返回数据,从浏览器控制台中该请求的 Preview 页签看得更美观一些。
检查请求是否成功:、
# 打印请求状态码,200说明请求成功,404说明找不到页面,等等
print(res.status_code)
200
**请求状态码的含义速记:**以 2 开头的状态码意味着请求成功,以 4 或 5 开头的状态码意味着请求失败,详情可参考 W3C’s Status Code Definitions。
print(records)
{"total": 582, "facets": {"market_cap": [{"value": 1, "count": 5916, "is_true": True}, {"value": 2, "count": 6792, "is_true": True}, {"value": 3, "count": 3370, "is_true": True}, {"value": 4, "count": 10731, "is_true": True}, {"value": 5, "count": 4249, "is_true": True}, {"value": 6, "count": 837, "is_true": True}, {"value": 7, "count": 711, "is_true": True}], "market_cap_13f": [{"value": 1, "count": 36037, "is_true": True}, {"value": 2, "count": 7683, "is_true": True}, {"value": 3, "count": 3152, "is_true": True}, {"value": 4, "count": 8663, "is_true": True}, {"value": 5, "count": 2167, "is_true": True}, {"value": 6, "count": 289, "is_true": True}, {"value": 7, "count": 178, "is_true": True}], "turnover_13f": [{"value": 1, "count": 11378, "is_true": True}, {"value": 2, "count": 768, "is_true": True}, {"value": 3, "count": 13493, "is_true": True}, {"value": 4, "count": 22213, "is_true": True}, {"value": 5, "count": 6041, "is_true": True}, {"value": 6, "count": 1202, "is_true": True}], "ranking": [{"value": 1, "count": 280, "is_true": True}, {"value": 2, "count": 387, "is_true": True}, {"value": 3, "count": 717, "is_true": True}, {"value": 4, "count": 2142, "is_true": True}, {"value": 5, "count": 23239, "is_true": True}, {"value": 6, "count": 31376, "is_true": True}], "pe": [{"value": 1, "count": 58169, "is_true": True}], "pe_next_year": [{"value": 1, "count": 58160, "is_true": True}, {"value": 3, "count": 5, "is_true": True}, {"value": 4, "count": 4, "is_true": True}], "price_sales": [{"value": 1, "count": 58169, "is_true": True}], "price_book": [{"value": 1, "count": 58169, "is_true": True}], "dividend_yield": [], "held_by": [{"value": 1, "count": 23428, "is_true": True}, {"value": 2, "count": 6744, "is_true": True}, {"value": 3, "count": 5776, "is_true": True}, {"value": 4, "count": 6298, "is_true": True}, {"value": 5, "count": 15223, "is_true": True}, {"value": 6, "count": 700, "is_true": True}], "filer_ids": [], "percent_change_in_shares_qoq": [{"value": 1, "count": 4694, "is_true": True}, {"value": 2, "count": 14889, "is_true": True}, {"value": 3, "count": 4335, "is_true": True}, {"value": 4, "count": 2435, "is_true": True}, {"value": 5, "count": 1501, "is_true": True}, {"value": 6, "count": 2229, "is_true": True}, {"value": 7, "count": 16354, "is_true": True}, {"value": 8, "count": 4097, "is_true": True}, {"value": 9, "count": 2374, "is_true": True}, {"value": 10, "count": 2182, "is_true": True}], "percent_change_in_filers_qoq": [{"value": 1, "count": 14783, "is_true": True}, {"value": 2, "count": 10969, "is_true": True}, {"value": 3, "count": 5392, "is_true": True}, {"value": 4, "count": 2806, "is_true": True}, {"value": 5, "count": 1765, "is_true": True}, {"value": 6, "count": 545, "is_true": True}, {"value": 7, "count": 11159, "is_true": True}, {"value": 8, "count": 4832, "is_true": True}, {"value": 9, "count": 2305, "is_true": True}, {"value": 10, "count": 539, "is_true": True}], "quarter_id": [{"value": 71, "count": 11767, "is_true": True}, {"value": 72, "count": 11701, "is_true": True}, {"value": 73, "count": 11611, "is_true": True}, {"value": 69, "count": 11588, "is_true": True}, {"value": 70, "count": 11502, "is_true": True}], "sector": [{"value": "FINANCE", "count": 18660, "is_true": True}, {"value": "UNKNOWN", "count": 7284, "is_true": True}, {"value": "HEALTH CARE", "count": 4859, "is_true": True}, {"value": "INFORMATION TECHNOLOGY", "count": 3745, "is_true": True}, {"value": "INDUSTRIALS", "count": 3502, "is_true": True}, {"value": "CONSUMER DISCRETIONARY", "count": 3447, "is_true": True}, {"value": "MUTUAL FUND", "count": 3406, "is_true": True}, {"value": "MATERIALS", "count": 2867, "is_true": True}, {"value": "ENERGY", "count": 2630, "is_true": True}, {"value": "REAL ESTATE", "count": 2372, "is_true": True}, {"value": "CONSUMER STAPLES", "count": 1622, "is_true": True}, {"value": "UTILITIES AND TELECOMMUNICATIONS", "count": 1556, "is_true": True}, {"value": "COMMUNICATIONS", "count": 1306, "is_true": True}, {"value": "TRANSPORTS", "count": 733, "is_true": True}, {"value": "UTILITIES", "count": 76, "is_true": True}, {"value": "Communications", "count": 60, "is_true": True}, {"value": "Utilities", "count": 22, "is_true": True}, {"value": "", "count": 10, "is_true": True}, {"value": "Consumer Staples", "count": 5, "is_true": True}, {"value": "Transports", "count": 4, "is_true": True}, {"value": "Health Care", "count": 3, "is_true": True}], "industry": []}, "records": 58169, "page": 1, "sort": "score", "dir": "desc", "rows": [{"id": "1470482", "score": None, "permalink": "aeis", "symbol": "AEIS", "name": "ADVANCED ENERGY INDUSTRIES INC", "held_by": 292, "market_cap": 2306173000.0, "market_cap_13f": 2132144670.0, "dividend_yield": None, "pe": None, "turnover": 28.343948, "percent_change_in_mv_qoq": -8.273920042454789, "percent_change_in_shares_qoq": 0.8444298, "percent_change_in_filers_qoq": -7.0063696, "pe_next_year": None, "average_ranking": 902, "quarter": "Q2 2018", "sector": "INFORMATION TECHNOLOGY", "industry": "SEMICONDUCTORS"}, ...]}
返回的 json 里(从浏览器请求的 Preview 页签中看),records 字段是总数据量,rows 是每页请求的数据量,total 字段是根据 rows 的总页数,利用这些信息,我们可以估计爬取时间,从而合理地调整速度和每页请求量。
由于学习的目的,爬取速度在允许的情况下尽量限制得慢一点,避免影响对方服务器正常运行。
print('总数据量:%s' % records['records'])
print('每页数据量:%s' % len(records['rows']))
min_request_time = records['records']//len(records['rows']) + 1
print('最少请求次数:%s 次' % (min_request_time))
print('爬取速度设定为:每 %.2f 秒请求一次' % speed_rate)
expected_time_spend = min_request_time*speed_rate
print('预计耗时:%.2f 秒 = %.2f 分钟 = %.2f 小时' % (expected_time_spend, expected_time_spend/60, expected_time_spend/3600))
若以上语法看不懂,请复习 Python 格式化字符串。
输出结果:
总数据量:58169
每页数据量:100
最少请求次数:582 次
爬取速度设定为:每 2.00 秒请求一次
预计耗时:1164.00 秒 = 19.40 分钟 = 0.32 小时
之前,连续翻页时分析请求,我们发现 URL 中只有 page 参数发生了变化。因此,要想爬取全部数据,我们只需写一个循环,每次循环改变 page 参数值,就可以爬下全部页面的数据了。
# 定义一个空数组,用于存放爬下来的全部数据
result_data = []
# 循环爬取每一个页面,数据写入刚才的空数组中
for i in range(min_request_time):
# 使用格式化字符串的语法,先生成 URL
url = 'https://whalewisdom.com/dashboard/stock_screener_query?rows=%s&page=%s&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69' % (row_per_page, i+1)
# 发起请求,打印请求的状态和 URL。这样爬虫运行的时候可以把握进度。
res = requests.get(url)
print('%s %s' % (res.status_code, res.url))
records = res.json()
# 数据就在每个 json 返回结果的 rows 字段中,前面已分析。
data = records['rows']
# 重命名变量,并把结果追加写入数组中
for row in data:
result_data.append({
'Quarter': row['quarter'],
'Name': row['name'],
'Ticker': row['symbol'],
'Sector': row['sector'],
'Industry': row['industry'],
'# Held_By': row['held_by'],
'Overall_Market_Cap': row['market_cap'],
'13F Market Cap ': row['market_cap_13f'],
'QoQ % Change in 13F Market Cap': row['percent_change_in_mv_qoq'],
'13F Turnover ': row['turnover'],
'Avg 13F Ranking ': row['average_ranking'],
'% Change in Filers': row['percent_change_in_filers_qoq'],
'% Change in Shares': row['percent_change_in_shares_qoq']
})
# 十分重要,让程序在指定时间后才继续进入下一次循环,这里是 2 秒,speed_rate = 2
# 限制了爬虫请求速度最快为 2 秒一次
time.sleep(speed_rate)
爬虫项目的网络数据采集部分到此完成,循环结束后,result_data 变量即为爬取得到的数据。接下来我们将数据写入 Excel 表格中。
储存数据
写入 Excel 也很简单,使用开头引入的 pandas 库即可。
# 定义变量在表格中展示的顺序
result_order = [
'Quarter',
'Name',
'Ticker',
'Sector',
'Industry',
'# Held_By',
'Overall_Market_Cap',
'13F Market Cap ',
'QoQ % Change in 13F Market Cap',
'13F Turnover ',
'Avg 13F Ranking ',
'% Change in Filers',
'% Change in Shares'
]
# 使用 result_data 数组生成数据表格 DataFrame 对象,这里 pd 来自最开始引入的 pandas 库
result_df = pd.DataFrame.from_records(data = result_data)
# 调整变量在表格中展示的顺序
result_df = result_df[result_order]
# 将 DataFrame 对象写入 Excel 文件中,文件名为 data.xlsx,Sheet 名为 data
result_df.to_excel("data.xlsx", sheet_name='data', index = False)
若在 Jupyter Notebook 中运行,直接执行
result_df也可以看到最终的数据表。
完整代码
# web_scrapy.py
import time # 时间库,这里用于限制爬取的速度,否则程序的请求过快,可能影响到对方服务器的正常运行
import requests # 访问互联网的库,这里用于模拟浏览器发送请求,并接受返回数据
import pandas as pd # 数据处理库,这里用于将数据写入 Excel
# 配置
speed_rate = 2
row_per_page = 100
# 预先请求一次,估计爬虫时间等信息
res = requests.get('https://whalewisdom.com/dashboard/stock_screener_query?rows=%s&page=1&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69' % (row_per_page))
records = res.json()
# print(res.status_code)
# print(records)
print('总数据量:%s' % records['records'])
print('每页数据量:%s' % len(records['rows']))
min_request_time = records['records']//len(records['rows']) + 1
print('最少请求次数:%s 次' % (min_request_time))
print('爬取速度设定为:每 %.2f 秒请求一次' % speed_rate)
expected_time_spend = min_request_time*speed_rate
print('预计耗时:%.2f 秒 = %.2f 分钟 = %.2f 小时' % (expected_time_spend, expected_time_spend/60, expected_time_spend/3600))
# 下面爬取全部页面的数据
# 定义一个空数组,用于存放爬下来的全部数据
result_data = []
# 循环爬取每一个页面,数据写入刚才的空数组中
for i in range(min_request_time):
# 使用格式化字符串的语法,先生成 URL
url = 'https://whalewisdom.com/dashboard/stock_screener_query?rows=%s&page=%s&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69' % (row_per_page, i+1)
# 发起请求,打印请求的状态和 URL。这样爬虫运行的时候可以把握进度。
res = requests.get(url)
print('%s %s' % (res.status_code, res.url))
records = res.json()
# 数据就在每个 json 返回结果的 rows 字段中,前面已分析。
data = records['rows']
# 重命名变量,并把结果追加写入数组中
for row in data:
result_data.append({
'Quarter': row['quarter'],
'Name': row['name'],
'Ticker': row['symbol'],
'Sector': row['sector'],
'Industry': row['industry'],
'# Held_By': row['held_by'],
'Overall_Market_Cap': row['market_cap'],
'13F Market Cap ': row['market_cap_13f'],
'QoQ % Change in 13F Market Cap': row['percent_change_in_mv_qoq'],
'13F Turnover ': row['turnover'],
'Avg 13F Ranking ': row['average_ranking'],
'% Change in Filers': row['percent_change_in_filers_qoq'],
'% Change in Shares': row['percent_change_in_shares_qoq']
})
# 十分重要,让程序在指定时间后才继续进入下一次循环,这里是 2 秒,speed_rate = 2
# 限制了爬虫请求速度最快为 2 秒一次
time.sleep(speed_rate)
# 定义变量在表格中展示的顺序
result_order = [
'Quarter',
'Name',
'Ticker',
'Sector',
'Industry',
'# Held_By',
'Overall_Market_Cap',
'13F Market Cap ',
'QoQ % Change in 13F Market Cap',
'13F Turnover ',
'Avg 13F Ranking ',
'% Change in Filers',
'% Change in Shares'
]
# 使用 result_data 数组生成数据表格 DataFrame 对象,这里 pd 来自最开始引入的 pandas 库
result_df = pd.DataFrame.from_records(data = result_data)
# 调整变量在表格中展示的顺序
result_df = result_df[result_order]
# 将 DataFrame 对象写入 Excel 文件中,文件名为 data.xlsx,Sheet 名为 data
result_df.to_excel("data.xlsx", sheet_name='data', index = False)
运行爬虫与成果
运行该 py 文件即可。
- 相同目录下打开命令行,执行
python web_scrapy.py即可 - 也可以将代码复制进 Jupyter Notebook 运行
- 可以使用 VS Code 运行和调试该文件
输出结果如下示例,每2秒会发起一个新请求,因而每两秒打印一条请求记录,作为爬虫日志。
总数据量:58169
每页数据量:100
最少请求次数:582 次
爬取速度设定为:每 2.00 秒请求一次
预计耗时:1164.00 秒 = 19.40 分钟 = 0.32 小时
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=1&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=2&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=3&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=4&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=5&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=6&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=7&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=8&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
200 https://whalewisdom.com/dashboard/stock_screener_query?rows=100&page=9&sidx=score&sord=desc&or_filers=0&quarter_id[]=73&quarter_id[]=72&quarter_id[]=71&quarter_id[]=70&quarter_id[]=69
...
得到 Excel 数据文件(示例,可能顺序有所差别):
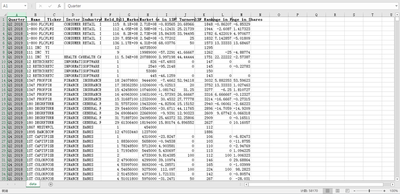
结语
这是一个非常简单的爬虫,但一开始没有经过那些请求分析的话,入门可能依然毫无头绪,写的爬虫也会更为复杂。
在更严谨的爬虫中,我们需要用 try...except...finally... 语法对请求失败的情况进行处理(比如重试请求等等),这样能避免因为一个小的请求错误导致整个爬虫中断。只需微调代码即可(关于该语法可复习这里)。
在这个爬虫中,我们通过翻页的动作找到了浏览器请求新数据的关键请求,从而能直接构造这个请求得到数据。在另一些情况中,这个关键请求难以捕获,如果捕获不到数据生产的“过程”,那么我们只能从我们看到的最终网页“结果”出发,用程序(Python 的 BeautifulSoup4 库)来解析最终的 html 网页文件,从众多标签中分离出我们需要的数据储存起来,那种方法显然也能爬取本文所爬取的网站~~(下一篇入门教程就决定是它了)~~,但它不比本文的这类方法高效(还需要额外处理该网站的动态加载问题),得到的数据精度(对比网页数据和请求的数据可以看出这一点)、运行效率也不如直接捕获“过程”的这类程序来得好,那种方法是本文这类方法行不通时的另一个通用策略,也仍是值得进一步学习的重要技术之一。
Hengzhao Hong
Ph.D Student in Statistics, Front-End Engineer
创造的过程,大多是“赝品”最终战胜“正品”的过程——从模仿开始,直至超越。